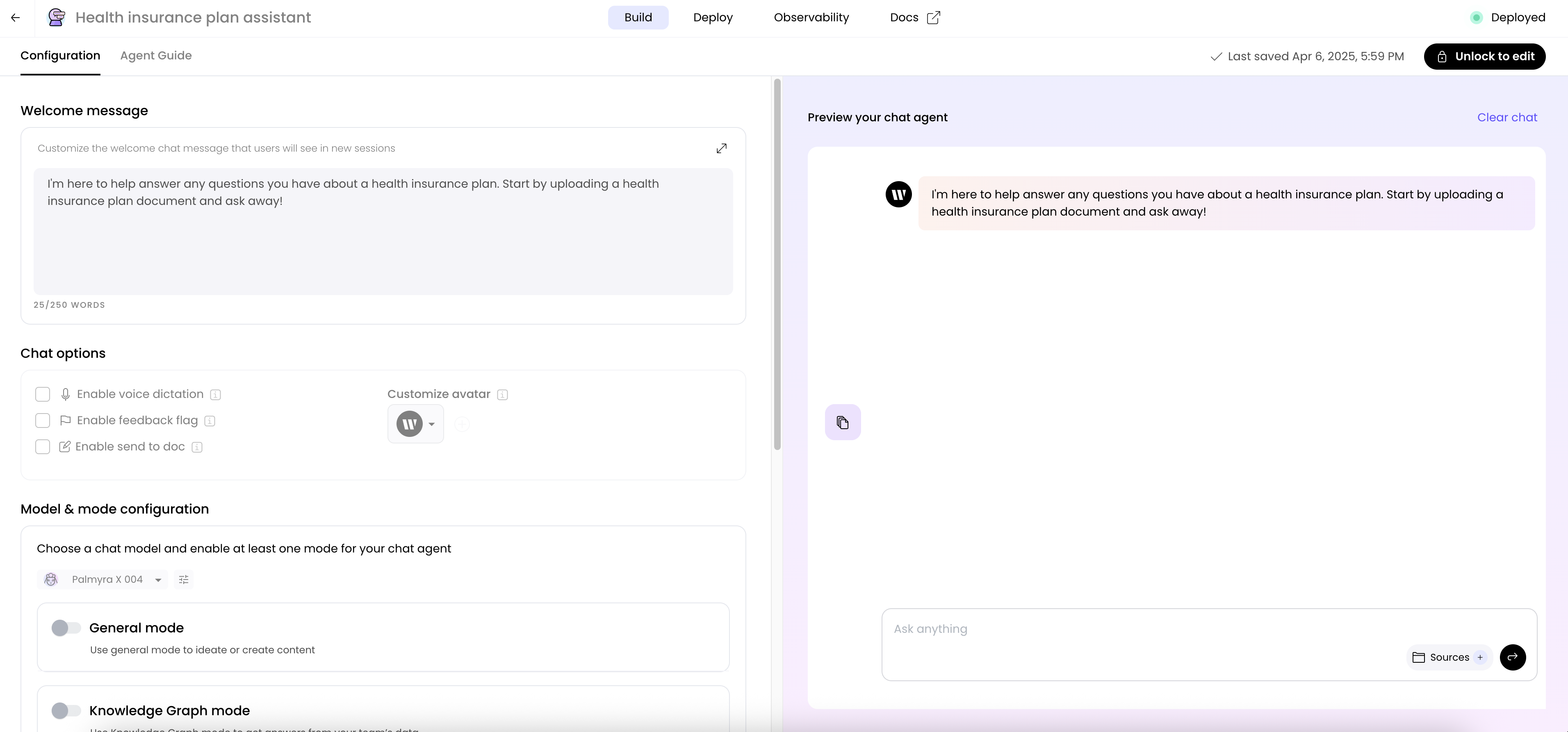
Building an agent with chat
To build an agent with chat capabilities, choose the Chat option after clicking Build an agent in AI Studio.
Write a welcome message
Next, create a welcome message. A welcome message is the first message your users see. Greet them, tell them how to use the chat, and include any special instructions or anything else they should know.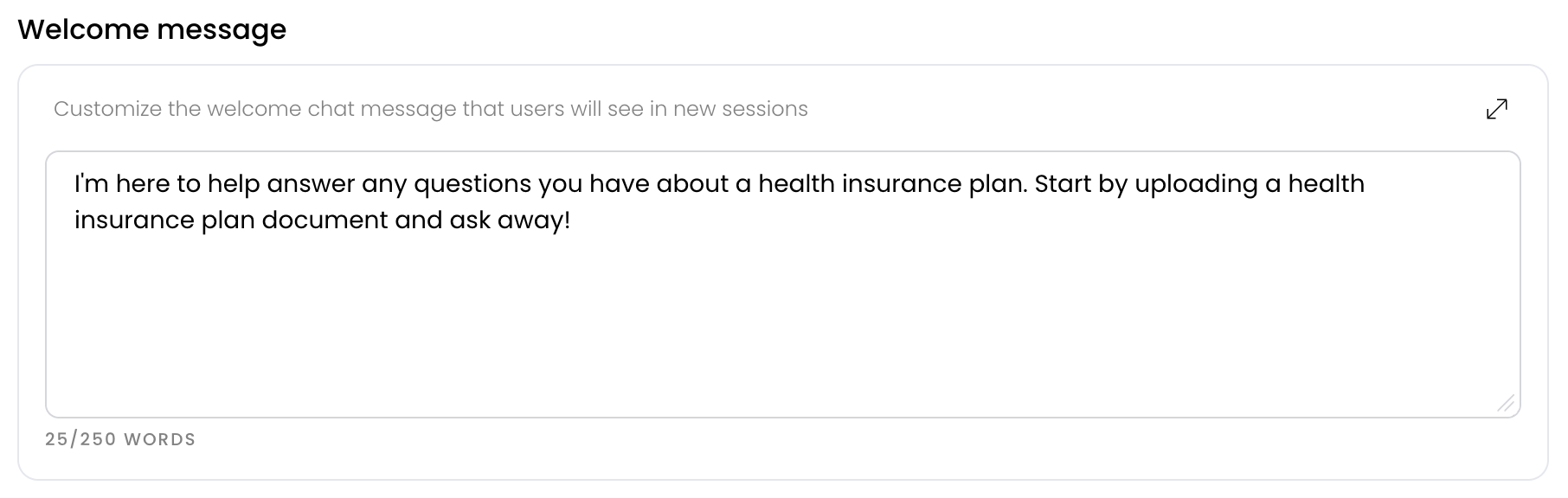
Create an avatar
Choose an avatar for your chat. This can be your company logo or any other image you prefer. Currently only .svg files are supported.
Choose a mode
To choose the right mode for your chat, decide how your users should interact with the agent. If you want users to ask general questions, choose the General chat mode. If you want users to ask specific questions about your company’s data, choose the Knowledge Graph mode. If you want users to ask questions about specific documents they provide, choose the Document mode. You can also select multiple modes for your agent. The following modes are available:- General chat mode: Use this mode to ideate or create content
- Knowledge Graph mode: Use this mode to get answers from your company’s data stored in a Knowledge Graph. Before you can use Knowledge Graph mode, you need to set up a Knowledge Graph with all the relevant information for your use case. For more granular control over how the agent answers questions using Knowledge Graph, see Configure Knowledge Graph settings.
- Document mode: Use this mode to answer questions about specific documents users provide. You can specify the number, types, and sources of documents you want to allow users to upload. You can also choose to allow users to add URLs or copy and paste text.
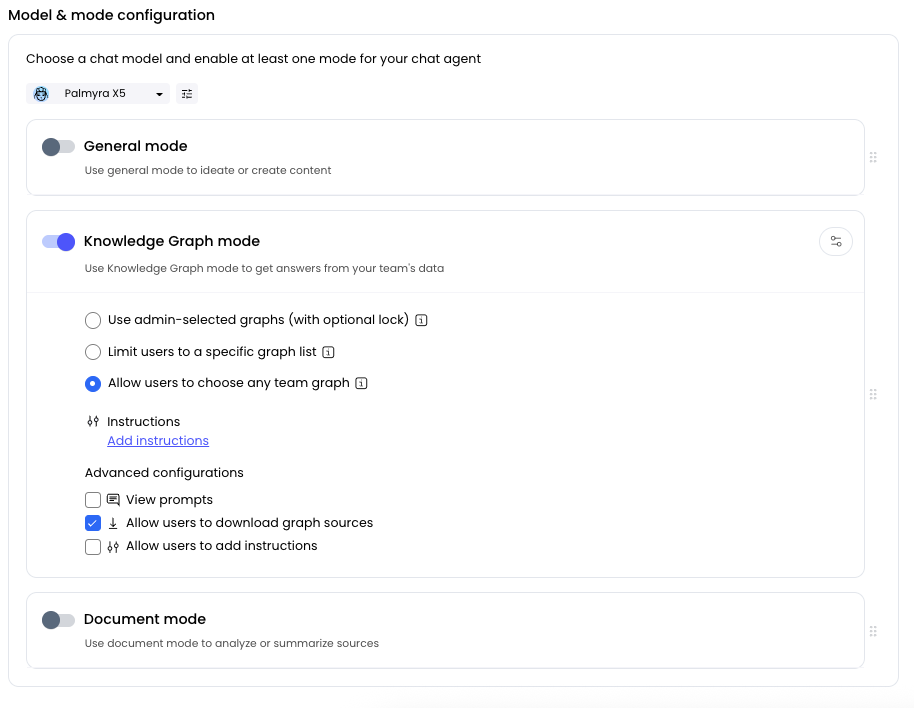
Provide instructions
All of the modes allow you to provide instructions. Instructions are the system messages that reach the LLM to provide context or structure around how your chat responds to requests.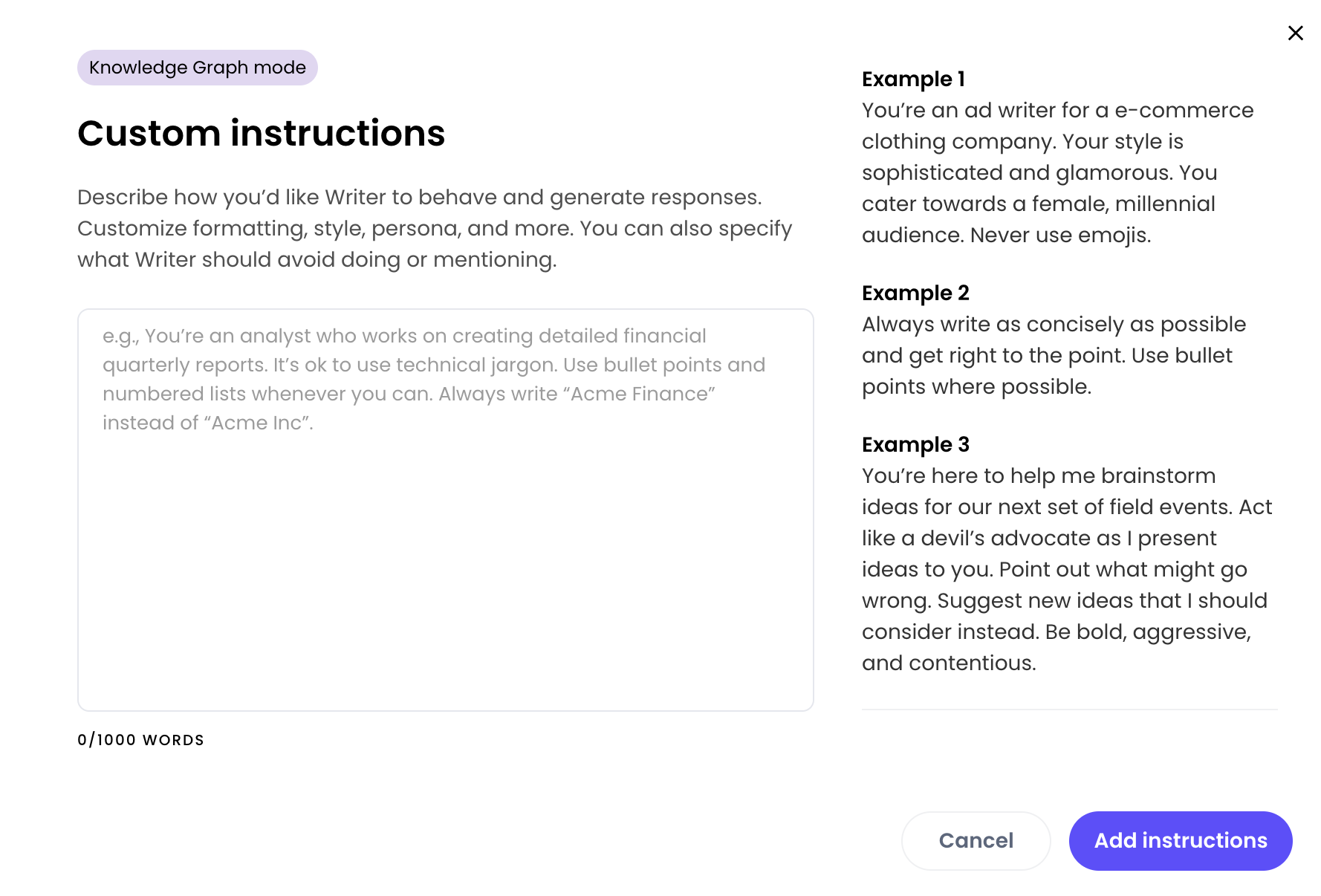
- Request answers in a specific language by providing examples.
- Patch stale data in your Knowledge Graph that’s hard to retrieve by providing additional information.
- Provide context about the users and how to address them.
- Set limits on the topics that the agent can answer.
Configure Knowledge Graph settings
When you enable Knowledge Graph mode for a chat agent, you can access advanced configuration options to fine-tune how the agent searches, ranks, and retrieves content from your Knowledge Graph. These settings control the balance between keyword and semantic search, how closely responses match source material, relevance thresholds, and response length.
Access configuration options
To configure Knowledge Graph settings for your chat agent:- Enable Knowledge Graph mode: In your chat agent configuration, turn on the Knowledge Graph mode toggle
- Open configuration: Click the configuration slider in the top right corner of the Knowledge Graph mode box when Knowledge Graph mode is enabled
- Adjust settings: Use the sliders and options in the configuration panel to customize behavior
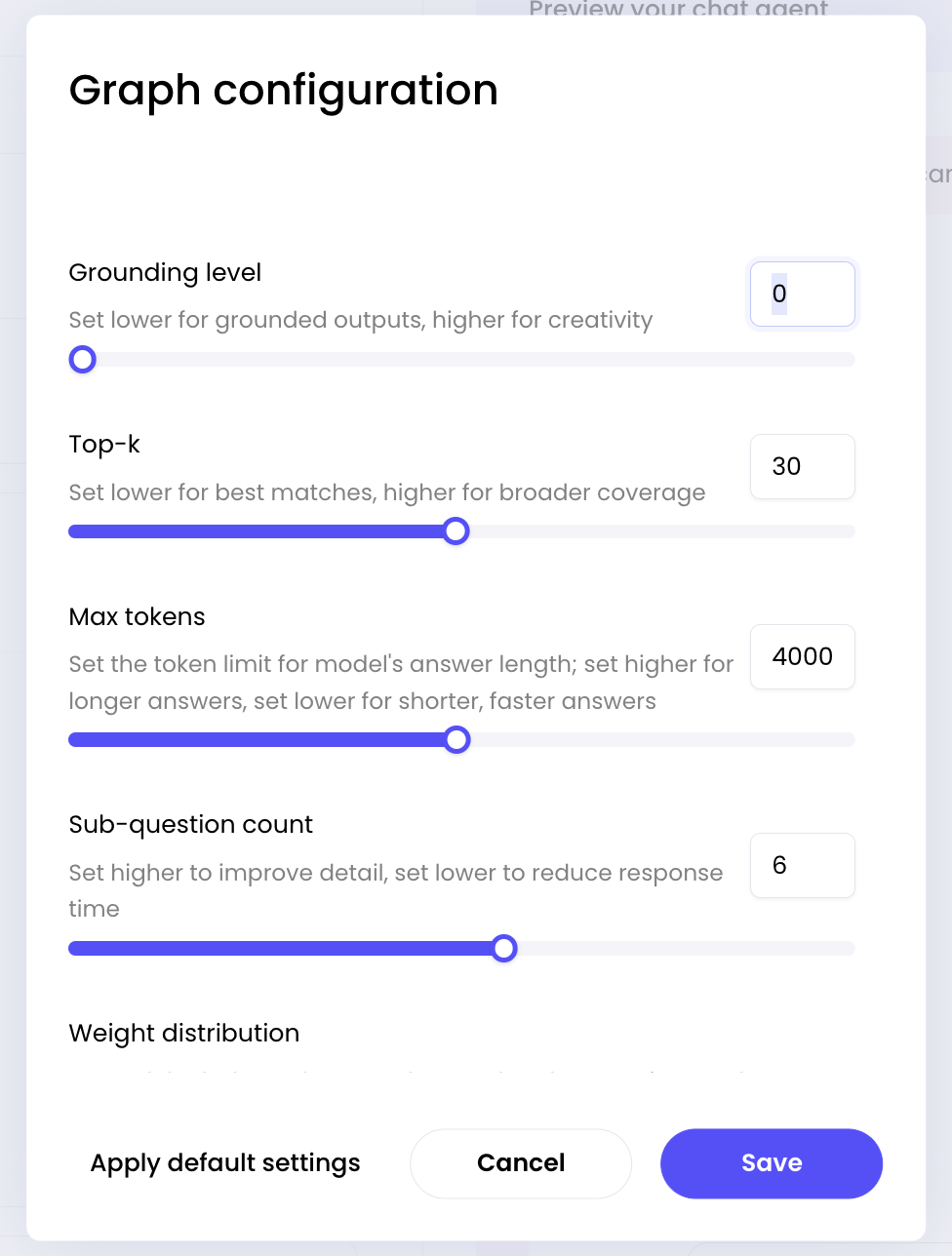
Configuration parameters
Grounding level
Controls how closely responses must match source material. This setting determines how much creative interpretation the AI can apply to Knowledge Graph content. How it works:- Lower values (closer to 0): Grounded outputs - stick closely to source material with minimal creativity
- Higher values (closer to 1): Higher creativity - allow more creative interpretation of source material
0.0: “According to the documentation, the API supports JSON responses” (direct quote/paraphrase)0.5: “The API documentation indicates that JSON responses are supported, which suggests additional capabilities” (interpretive)1.0: “Based on the available information, users can expect JSON responses, though other formats might be possible” (highly interpretive)
- Increase for higher creativity when you want more interpretive responses
- Decrease for grounded outputs when factual reporting or accuracy is critical
Top-k
Controls the balance between keyword and semantic search in ranking results. This parameter determines how the system prioritizes different types of matching. How it works:- Higher values (closer to 100): Prioritize keyword-based matching
- Lower values (closer to 0): Prioritize semantic similarity matching
- Increase for searches where exact keyword matches matter most
- Decrease for searches where conceptual similarity is more important
Max tokens
Maximum number of tokens the model can generate in the response. This controls the length of the AI’s answer. How it works:- Higher values: Allow longer, more detailed responses
- Lower values: Generate shorter, more concise responses
- Increase for detailed analysis or comprehensive answers
- Decrease for quick summaries or when you need faster responses
Sub-question count
Maximum number of sub-questions to generate when processing complex queries. Higher values allow the system to break down complex questions into more detailed sub-queries. How it works:- Higher values: Improve detail by generating more sub-questions for thorough analysis
- Lower values: Reduce response time by generating fewer sub-questions
- Increase for complex, multi-part questions that need thorough analysis
- Decrease for simple, direct questions to reduce processing time
Weight distribution
Controls how many text snippets to retrieve from the Knowledge Graph for context. This works together with the Top-k setting to control best matches vs broader coverage. How it works:- Lower values (5-15): Best matches - retrieve fewer, more relevant snippets
- Higher values (15-25): Broader coverage - retrieve more snippets for comprehensive context
- Values below 5: May return no results due to RAG implementation limitations
- Recommended range: 5-25 (default is 30, which is higher than recommended)
- Due to RAG system behavior, you may see more snippets than requested
- Increase for broader coverage when you need comprehensive research or more context
- Decrease for best matches when you want focused queries or concise results
Keyword relevance threshold
Controls how closely keyword matches must align with your query. Higher settings require closer matches, while lower settings allow broader keyword relevance in results. How it works:- Low: Broader range - includes results with looser keyword matches
- Medium: Balanced filtering for most use cases
- High: Stricter relevance - only includes results with strong keyword matches
- Set higher for stricter relevance when you need precise keyword matching
- Set lower for broader range when you want to capture more potential matches
Semantic relevance threshold
Controls how closely results must match the meaning of your query. Higher settings require stronger semantic similarity, while lower settings allow varied interpretations. How it works:- Low: Broader range - includes results with looser semantic connections
- Medium: Balanced filtering for most use cases
- High: Stricter relevance - only includes results with strong semantic similarity
- Set higher for stricter relevance when you need precise conceptual matching
- Set lower for broader range when you want to capture more contextually related content
Common configuration patterns
The default configuration for Knowledge Graph mode handles most use cases. You can adjust the configuration to your specific needs. Below are some common configuration patterns for different use cases.Research and analysis
Use this configuration for comprehensive research tasks where you need thorough analysis. Higher sub-questions and broader coverage provide more context. Settings:- Grounding level: 0.1 (very grounded)
- Top-k: 60 (balanced search)
- Max tokens: 7000 (detailed responses)
- Sub-question count: 8 (thorough analysis)
- Weight distribution: 25 (broad coverage)
- Keyword relevance threshold: Low (broader range)
- Semantic relevance threshold: Low (broader range)
Quick answers
Use this configuration for fast, focused responses where speed and precision matter more than comprehensive analysis. Settings:- Grounding level: 0.0 (completely grounded)
- Top-k: 80 (keyword-focused)
- Max tokens: 2000 (concise responses)
- Sub-question count: 3 (quick processing)
- Weight distribution: 15 (focused results)
- Keyword relevance threshold: High (stricter relevance)
- Semantic relevance threshold: High (stricter relevance)
Creative content generation
Use this configuration when you want the AI to interpret and build upon source material creatively. Settings:- Grounding level: 0.6 (interpretive)
- Top-k: 40 (semantic-focused)
- Max tokens: 5000 (moderate length)
- Sub-question count: 6 (balanced analysis)
- Weight distribution: 30 (comprehensive context)
- Keyword relevance threshold: Medium (balanced filtering)
- Semantic relevance threshold: Low (broader range)
How parameters work together
Some parameters interact in ways that affect both results and performance:- Weight distribution and Top-k: Work together to control best matches vs broader coverage
- Weight distribution and Max tokens: Weight distribution controls input context size, while Max tokens controls output response length
- Grounding level and Sub-question count: Both affect how thoroughly the system processes queries
Performance considerations
- Higher Max tokens: Increases processing time and cost
- Higher Sub-question count: Increases processing time for complex queries
- Lower Weight distribution: May return fewer results but with higher relevance
- Higher Grounding level: May require more processing to balance creativity with accuracy
Best practices
- Start with defaults: Begin with the default configuration and adjust based on your specific needs
- Test incrementally: Change one parameter at a time to understand its effect
- Consider your use case: Different applications, like research, Q&A, and content generation, benefit from different configurations
- Monitor performance: Track how different configurations affect response quality and processing time
- Balance precision and recall: Higher Top-k values give more precise results but may miss relevant content